

Web Scraping en Python avec BeautifulSoup
Qu'est-ce que le Web Scraping ?
Le web scraping est défini comme "l'extraction de données de sites web ou d'internet" et c'est exactement cela — utiliser du code pour lire automatiquement des sites web, rechercher quelque chose ou consulter le code source des pages afin d'en extraire certaines informations.
Ceci est utilisé partout, des robots Google indexant les sites web, à la collecte de données sur les statistiques sportives, en passant par l'enregistrement des cours boursiers dans un tableur Excel — les options sont vraiment illimitées. S'il y a un site, une page ou un terme de recherche qui vous intéresse et dont vous souhaitez avoir des mises à jour, alors cet article est pour vous — nous allons examiner comment utiliser les requests et BeautifulSoup bibliothèques pour recueillir des données à partir de sites web avec Python, et vous pourrez facilement transférer les compétences que vous apprendrez pour extraire des données de n'importe quel site web qui vous intéresse sans effort.
Quels outils allons-nous utiliser ?
Python est le langage de prédilection pour extraire des données d'Internet, et les requests et BeautifulSoup bibliothèques sont les packages Python incontournables pour ce travail. Avec requests, vous pouvez facilement extraire des données de n'importe quel site web et lire ses données de plusieurs façons, du HTML au JSON. Puisque la plupart des sites web sont construits en HTML et que nous allons extraire tout le HTML de la page, nous utiliserons ensuite le package BeautifulSoup de bs4 afin d'analyser ce HTML et de trouver les données que nous recherchons à l'intérieur.
Prérequis
Pour pouvoir suivre, vous devez avoir Python, requests, et BeautifulSoup installés.
-
Python : vous pouvez télécharger la dernière version de Python sur le site web officiel, bien qu'il soit très probable que vous l'ayez déjà installé.
-
requests: si vous avez une version Python >= 3.4, vous avezpipinstallé. Vous pouvez ensuite utiliserpipdans la ligne de commande en tapantpython3 -m pip install requestsdans n'importe quel répertoire. -
BeautifulSoup: cela est fourni avecbs4, mais vous pouvez simplement l'installer avecpython3 -m pip install beautifulsoup4.
Programmation
Je crois que la meilleure façon d'apprendre la programmation est de pratiquer et de construire un projet, donc je vous encourage vivement à me suivre dans votre éditeur de texte préféré (je recommande Visual Studio Code) pendant que nous apprenons à utiliser ces deux bibliothèques à travers un exemple.
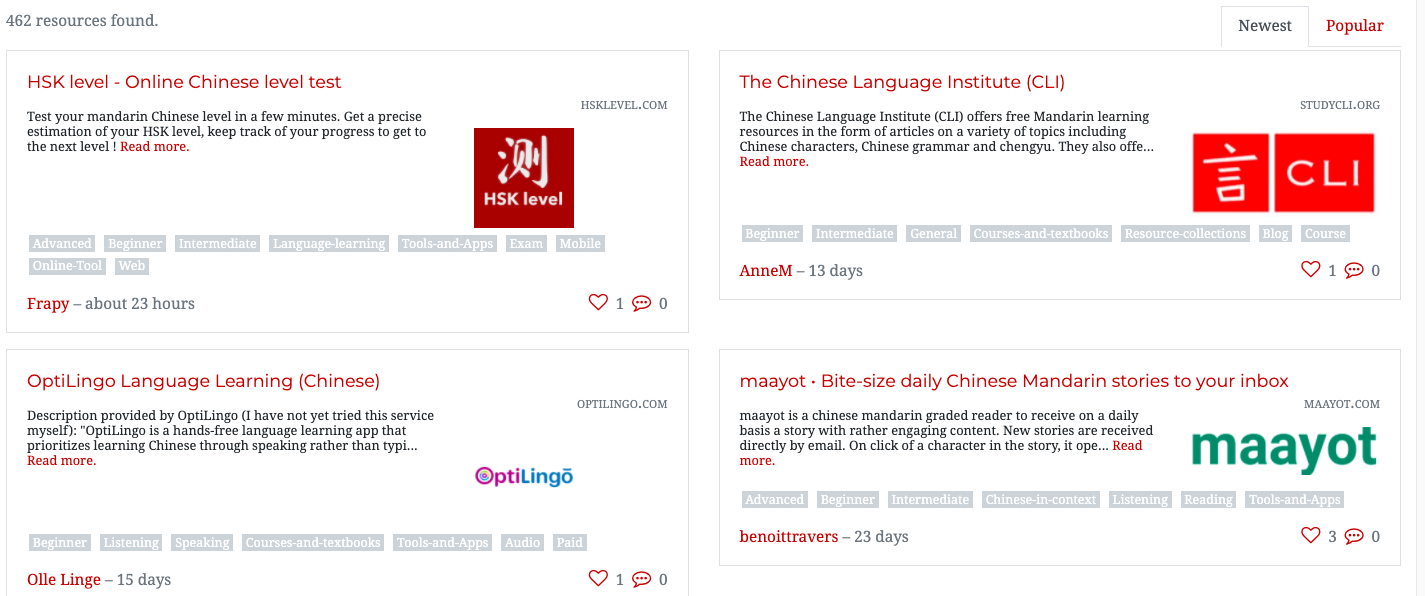
Comme j'apprends le mandarin, j'ai pensé qu'il serait approprié de créer un scraper qui génère une liste de liens vers des ressources en mandarin. Heureusement, j'ai fait quelques recherches au préalable et j'ai découvert qu'il existe un site web en ligne qui stocke des listes de ressources en mandarin sous forme de cartes. Cependant, celles-ci sont réparties sur près d'une douzaine de pages, sous forme de cartes, et beaucoup de liens sont brisés. Le site web que nous allons scraper pour obtenir ces liens est un site bien connu pour l'apprentissage du mandarin, et vous pouvez voir la liste des ressources ici : https://challenges.hackingchinese.com/resources.
Voici la traduction en français : Donc, dans ce projet, nous allons extraire les liens fonctionnels de cette liste et les enregistrer dans un fichier sur notre ordinateur, afin de pouvoir les parcourir plus tard à notre guise sans avoir à cliquer sur chaque carte du site. Le programme entier ne fera qu'environ 40 lignes de code, et nous travaillerons sur le projet en trois étapes individuelles.
Analyse du site
Avant de commencer la programmation proprement dite, nous devons voir où les données sont stockées sur le site web. Cela peut être fait en "Inspectant" la page. Vous pouvez inspecter une page en faisant un clic droit n'importe où dans la page, puis en sélectionnant "Inspecter". Si vous sélectionnez cela, le code source de la page s'affichera en bas de votre écran, un tas de HTML intimidant. Ne vous inquiétez pas - la BeautifulSoup bibliothèque nous facilitera la tâche.
Nous allons "Inspecter" le premier résultat sur le site web à https://challenges.hackingchinese.com/resources, à savoir HSK level — Online Chinese level test. Pour ce faire, nous devons placer notre souris juste au-dessus de ce que nous voulons extraire - qui est le titre, car c'est aussi un lien - puis cliquer sur "Inspecter", ce qui ouvrira le code source et nous amènera exactement où nous voulons être - au niveau du lien.
Si vous le faites, vous devriez voir quelque chose comme ci-dessous :
class="card-title" style="font-size: 1.1rem">
href="http://www.hsklevel.com">HSK level — Online Chinese level test
Bonne nouvelle ! Il semble que chaque lien soit à l'intérieur d'un en-tête h4. Lorsque nous extrayons des données d'un site web, nous devons rechercher l'"identifiant" unique de ces données. Dans ce cas, il s'agit de l'en-tête h4, car il n'y en a pas d'autres sur le site qui ne soient pas liés aux liens. Une autre option pourrait être de rechercher en fonction de font-size ou le class de card-title, mais nous opterons pour l'en-tête h4 car c'est le plus simple.
Scraping des liens de ressources
Maintenant que nous avons compris à quoi ressemble la source du site web, nous devons passer à l'extraction du contenu. Nous allons enregistrer chaque lien dans un fichier sur notre appareil nommé links.txt, et il ne faut que quelques dizaines de lignes pour y parvenir.
Commençons.
- Importation des bibliothèques
Nous avons besoin des bibliothèques mentionnées précédemment pour faire fonctionner le programme. Créez un nouveau fichier nomméscrape_links.pyet écrivez ce qui suit :
import requests, time de bs4 import BeautifulSoup - Extraction du site
Comme le site web a ses ressources réparties sur plusieurs pages, il est logique de les extraire dans une fonction que nous pourrons répéter. Appelons cette fonctionextract_resources, et elle aura un paramètre définissant son numéro de page.
def extract_resources(page: int -> None): # use an f-string to access the correct page page = requests.get(f'https://challenges.hackingchinese.com/resources/stories?page={page}) soup = BeautifulSoup(page.content, 'html.parser')Nous utilisons la variable
souppour contenir un objetBeautifulSoupdu site web. Nous le convertissons en HTML avechtml.parseret les données que nous convertissons sont le contenu de lapagevariable.links = soup.find_all('h4')Nous utiliserons
BeautifulSouppour trouver tout le HTML qui sont des en-têtes, et les enregistrerons dans une liste nomméelinksavec leur HTML enfant (dans ce cas, le lien). - Collecte de nos données
for i dans range(len(links)): try: if links[i]['class'] == ['card-title']: true_links.append(links[i]) except: passSur la première ligne, nous itérons à travers chaque en-tête h4 dans
links. Nous vérifions si sa classe estcard-title, comme nous l'avons vu dans Analyse du site, afin de nous assurer que nous évitons tous les en-têtes h4 qui ne sont pas des cartes — juste au cas où. S'il s'agit d'un h4 lié à une carte avec un lien, nous allons l'ajouter à la liste précédemment videtrue_linksavec tous les h4 correct .
Enfin, nous envelopperons ceci dans une boucletry: except:au cas où le h4 n'aurait pas de cas, pour empêcher le programme de planter carBeautifulSoupne peut pas gérer la requête. - Sauvegarde des liens
# open file with w+ (generate it if it does not exist) file = open("links.txt", "w+") for i dans range(len(true_links)): file.write(str(list(true_links[i].children)[0]['href']) + '\n') file.close()Au lieu d'imprimer la liste, sauvegardons-la pour ne pas avoir à exécuter le fichier Python plusieurs fois et l'avoir dans un format plus facile à visualiser.
Premièrement, nous ouvrons le fichier, et nous l'ouvrons avecw+afin que s'il n'existe pas, nous puissions générer un fichier vierge avec son nom.
Deuxièmement, nous itérons à travers la liste detrue_links. Pour chaque élément, nous écrivons dans le fichier avec son lien en utilisantfile.write(). Lorsque nous analysions le site pour la première fois, nous avons vu que le lien est un élément enfant de l'en-tête HTML h4. Donc, nous utilisonsBeautifulSouppour accéder au premier enfant detrue_links[i], que nous devons envelopper dans une liste car c'est autrement un objet Python.
À ce stade, nous avonslist(true_links[i].children)[0]. Cependant, ce que nous recherchons est le lien réel de l'enfant. Au lieu deTextnous voulons juste le lien, auquel nous pouvons accéder avec['href']. Une fois que nous l'avons, nous devons envelopper le tout dans une chaîne pour qu'il soit produit en tant que chaîne, puis ajouter '\n' afin de s'assurer que chaque lien est sur une nouvelle ligne lorsque nousfile.write()le.
Enfin, nous effectuonsfile.close()afin de fermer le fichier que nous avons ouvert.
Si vous exécutez le programme et lui donnez quelques minutes, vous devriez constater que vous avez maintenant un fichier nommélinks.txtavec des centaines de liens que nous avons récupérés avec Python ! Félicitations ! Sans Python, il aurait fallu beaucoup plus de temps pour saisir manuellement chaque URL.
Avant de terminer, nous allons voir une autre façon d'utiliser la bibliothèquerequestsen vérifiant le statut de chaque lien.
Bonus : Suppression des liens morts
Le site web que nous scrappons n'est pas maintenu en très bon état, et certains liens sont obsolètes ou totalement morts. Donc, dans cette étape facultative, nous allons voir un autre aspect du scraping qui renvoie le code d'état de chaque site web, et les écarte s'il s'agit d'un 404 — signifiant non trouvé.
Nous allons devoir légèrement modifier le code utilisé à l'Étape 4 ci-dessus. Au lieu de simplement parcourir les liens et de les écrire dans le fichier, nous allons d'abord nous assurer qu'ils ne sont pas cassés.
file = open("links.txt", "w+")
for i dans range(len(true_links)):
try:
# ensure it is a working link
response = requests.get(str(list(true_links[i].children)[0]['href']), timeout = 5, allow_redirects = True, stream = True)
if response != 404:
file.write(str(list(true_links[i].children)[0]['href']) + '\n')
except: # Connection Refused
pass
file.close()
Nous avons apporté quelques changements — passons-les en revue.
- Nous avons créé une variable
responsequi vérifie le code d'état du lien — essentiellement pour voir s'il est toujours là. Cela peut être fait avec la méthode utilerequests.get()Nous obtenons le même lien que celui que nous essayons d'ajouter, à savoir l'URL du site web, et nous lui donnons 5 secondes pour répondre, la possibilité de rediriger, et nous lui permettons de nous envoyer des fichiers (que nous ne téléchargerons pas), avecstream = True. - Nous avons vérifié quelle était la réponse, en voyant si c'était un 404 ou non. Si ce n'était pas le cas, nous avons écrit le lien, mais si c'était le cas, nous n'avons rien fait et n'avons pas écrit le lien dans le fichier. Cela a été fait par la condition
if response != 404. - Enfin, nous avons enveloppé le tout dans une boucle try — except. C'est parce que si la page était lente à charger, inaccessible, ou si la connexion était refusée, le programme planterait normalement dans une Exception. Cependant, comme nous l'avons enveloppé dans cette boucle, rien ne se passera en cas d'Exception et elle sera simplement ignorée.
Et voilà ! Si vous exécutez le code (et le laissez tourner aussi, car pour requests vérifier des centaines de liens, cela peut prendre une bonne demi-heure) lorsqu'il aura fini, vous aurez un bel ensemble de quelques centaines de liens de ressources fonctionnels !
Code complet
# grab the list of all the resources at https://challenges.hackingchinese.com/resources
import requests, time
de bs4 import BeautifulSoup
# links that hold the correct content, not headers and other HTML
true_links = []
def extract_resources(page: int) -> None:
page = requests.get(f'https://challenges.hackingchinese.com/resources/stories?page={page}')
soup = BeautifulSoup(page.content, 'html.parser')
# links are stored within a unique header on each card
links = soup.find_all('h4')
for i dans range(len(links)):
try:
if links[i]['class'] == ['card-title']:
true_links.append(links[i])
except:
pass
for i dans range(1, 10):
extract_resources(i) # 9 different pages with info
file = open("links.txt", "w+")
for i dans range(len(true_links)):
try:
# ensure it is a working link
response = requests.get(str(list(true_links[i].children)[0]['href']), timeout = 5, allow_redirects = True, stream = True)
if response != 404:
file.write(str(list(true_links[i].children)[0]['href']) + '\n')
except: # Connection Refused
pass
file.close()
Conclusion
Dans cet article, nous avons appris à :
- Visualiser le code source d'une page
- Extraire des données spécifiques d'un site web
- Écrire dans des fichiers avec Python
- Vérifier les liens morts
Bien que nous n'ayons qu'effleuré la surface du type d'extraction de données web qui peut être fait en Python avec les bibliothèques appropriées, j'espère que même cette brève introduction vous a appris comment exploiter la puissance de la programmation pour extraire automatiquement des sites web. Je vous encourage vivement à consulter la documentation officielle de requests et BeautifulSoup si vous voulez plonger plus profondément dans le monde de l'extraction de données, et voir s'il y a des données que vous peut recueillir sur le web et utiliser dans vos propres projets.
Faites-moi savoir dans les commentaires ce que vous êtes en train de scraper ou si vous avez besoin d'aide supplémentaire !
Bon codage !
Laisser un commentaire